The quality of insights that you can expect to glean from clickstream data is directly dependent upon the quality of meta-data that you can attach to visitor sessions taking place on your digital properties. Visits, pageviews, bounce rates, card abandonments etc. are all great metrics but their utility wanes when it comes to their ability to provide any actionable intelligence about advanced efficiency metrics (attribution, channel ROI etc.) and effectiveness metrics (think strategic business outcomes like market share, share of wallet etc.). Such advanced metrics inevitably require combining data from various sources and businesses must make informed decisions about the best approach to implementing this analytics rigor in line with business priorities, resource availabilities and commercial constraints.
In this post, we discuss the importance of tagging within the context of digital data mining and outline 3 different implementation approaches. More specifically, we contrast the limitations of various tagging approaches when dealing with advanced data analysis scenarios and how they impact decision making.
Digital data collection-The technology options
The common vocabulary used for enriching clickstream data is tagging. For the purpose of a wider discussion around digital insights though, we swap the word tagging with Digital data collection. A capability that can be implemented using 3 distinct approaches.
 Plain JavaScript-Tech-savvy Analysts would already be aware of how JavaScript tags are typically used in conjunction with pixel-based tracking techniques (think Google Analytics, Coremetrics, Adobe Analytics etc.) to capture data about important events relevant for specific business context. While this technique was (and continues to be) the predominant method for collecting digital behavior data, the method has its limitations in terms of how effectively and efficiently can the data be collected and the ease with which it can be assimilated to provide advanced digital intelligence.
Plain JavaScript-Tech-savvy Analysts would already be aware of how JavaScript tags are typically used in conjunction with pixel-based tracking techniques (think Google Analytics, Coremetrics, Adobe Analytics etc.) to capture data about important events relevant for specific business context. While this technique was (and continues to be) the predominant method for collecting digital behavior data, the method has its limitations in terms of how effectively and efficiently can the data be collected and the ease with which it can be assimilated to provide advanced digital intelligence.- Using Tag Management Technology-Tag managers provide an alternative to the direct JavaScript tags-based data collection approach but come with their own limitations around getting insights for metrics that were not originally planned when the data layer was put in place or where merging with offline datasets is required.
- Server-side tagging-This is the most flexible but the most resource and cost intensive approach to data collection and involves creating meta-data on the fly instead of using JavaScript based tags.
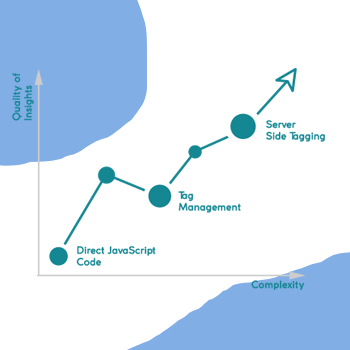
The complexity, resource requirements, and benefits of each of these approaches grow progressively and it helps to have a clear appreciation of the pros and cons of each for specific business scenarios.
The Business Context
For technology implementations to be commercially successful, they must address specific business needs within constraints of time, resource availability and budget. Consider the following scenarios-
Scenario 1- Online only SaaS business
Consider a simple use case of an online-only SaaS business that is just starting out with its analytics journey. Basic metrics such as page views, unique sessions, newsletter signups, CRM leads, collateral downloads etc. would likely be enough as a starting point to building an optimization agenda. The company is likely using simple lead capture forms with inbuilt support for plugging into tools such as Google Analytics. In such cases, simple JavaScript snippets are written directly within the CMS (e.g. within WordPress child themes) would likely be enough to send any additional data into the analytics tracking tool. Small team sizes, in-frequent website code updates, single installation web properties, and an online-only acquisition channel are some of the factors that make it perfectly fine to simply use vanilla JavaScript coding to enrich basic clickstream data already captured by the web analytics tool.
In terms of technology options, tools such as Google Analytics, Mixapanel, and Kissmetrics can be easily set up to use JavaScript based coding approach.
Scenario 2 – Mid-sized media publisher (online only) with multiple properties
Now consider the scenario of a media publisher whose business model relies heavily upon how well it can monetize its digital properties. The publisher operates multiple sites for varying audience categories but all of them must follow the same underlying analytics architecture. Consider that this company is looking to roll-out an analytics solution that will help better quantify digital engagement, so it can use the stats to demand better pricing for its digital inventory. So, for example, the company may be looking to segment its users based on various behavioral signals that the visitors exhibit as they browse through the company’s media properties. A Technology advertiser looking to target its content specifically to engaged and in-market C-level audience would likely pay a higher price for ad exposure if the company can show the advertiser’s ads specifically to cookies that meet this criterion.
How can this be implemented technically? Behavioral signals that are used in assessing engagement are generated as the user interacts with a website. Is it still advisable to capture these using plain JavaScript? Perhaps not. Consider the following arguments to understand why-
- The company has multiple web properties with different HTML markup. Building out code that reads directly from HTML DOM can be highly problematic in that the changes will have to be implemented separately for every DOM variation. For example, consider that we need to tag all visitors who come from a specific campaign, interact with an article in a certain manner (spend > x secs on the page, reach section y of the page etc.). Site A identifies all such articles of interest as HTML id ‘A’ while Site B uses different identifiers. How do we write JavaScript code once and make it work across HTML DOM variations?
- Every digital property has its own release cycle which means that putting the code into production cannot happen simultaneously if we were injecting JavaScript code directly into web pages. This will likely present significant reporting challenges when conveying campaign performance figures to Clients.
- The specific signals that define ‘intent’ may be a matter of experiment and involve trying out different JavaScript code before adding a cookie to a segment. For example, the first iteration might assume engagement to be consisting of
- Visitor spending > x seconds on an article
- No exit from the landing page
- At least one follow-up interaction (submit a query, phone call, online webinar registration etc.)
However, the company might want to try out different such conditions and then run A/B tests to identify the most relevant definition of engagement. All this requires a significant amount of testing with JavaScript coding variations and having a dependency on bureaucratic code release cycles can be a significant drag in the marketing team’s ability to provide answers to sales teams about exactly what constitutes engagement.
- The operational issues around maintaining JavaScript code that must change every time the HTML markup is changed can be simply unmanageable and cost prohibitive. Consider the process nightmares involved in having to communicate code changes to a central team or worst, having to take formal approvals before making HTML DOM changes!
As readers would hopefully agree, directly injecting JavaScript code into HTML pages may no longer be a viable option in this specific scenario. A better approach would be to use a Tag Manager solution that can provide the following benefits
- Tag Managers use an intermediate data layer that can decouple server-side logic from HTML markup. For example, instead of having separate code on site A that counts the number of downloads of a form with div id ‘A’ and then another code on site ‘B’ that identifies the same form with div id ‘B’, we could write and deploy a single snippet that fires for every value in an intermediate JavaScript variable ‘C’. This variable would be populated at the time of page load and would require no changes in the client-side JavaScript code.
- As long as an intermediate canonical data format is used (a.k.a. the data layer), individual website owners would have the flexibility in using whatever HTML markup that they have been using historically and not run the risk of break existing functionality.
- One of the biggest USPs of the Tag Management approach would be that all changes to JavaScript tags can be implemented centrally as opposed to on individual properties. This would allow not just the centralization of Technical Architecture but also significantly reduce the time taken to roll out tag changes.
But of course, these benefits come with additional costs and implementation complexities and every business must make its own unique assessment around which approach might suit better given a set of constraints about business requirements, skills availability, and time/budget constraints. In terms of technology options though, tools such as Google Tag Manager, Qubit, Ensighten can all be considered as viable platform choices.
Scenario 3 – B2B Software vendor catering to enterprise Clients
The 2 scenarios above focused entirely on tracking behavior online. But what if analysis needs require working with a combination of online/offline datasets? Consider a large B2B Software Company that captures leads online but where the actual conversion happens after a number of interactions with the website, webinar presentations, offline events, and sales team calls. How does this company profile and segment its prospects and customers? Can we still feasibly send interaction data from multiple channels into the analytics tool via the Tag Management solution? Perhaps not. Consider some reasons as to why not-
- Every interaction would have a different customer/prospect identifier. Even if you could somehow send in offline data into the analytics tool, you would still need to bring data out to create a single profile that combines the data from different events into a record with a common identifier. Tag Manager and certainly basic web analytics tools such as Google Analytics are simply not designed for this use case.
- Most large companies have enterprise-level data warehouses and advanced business intelligence tools that are purpose-built for aggregating and analyzing complex data sets created from varied sources. Going off the established Enterprise Architecture would almost always be resisted by most IT teams.
A better approach in this scenario would be to deploy a server-side tagging architecture which allows not just attaching arbitrary metadata to visitor level clickstream records but also facilitates complex ETL operations through integration with leading data integration tools. In the example above, instead of sending interaction data into the web analytics tool, we would record the cookie ID in CRM as soon as a lead is generated online and associate this with a unique CRM identifier. Using this cookie id, we would then regularly pull all web behavioral data into an intermediate data store and merge it with data from offline interactions such as event attendance, roadshow participations, webinar registrations on third-party sites etc. Having a unified profile of every visitor and which combines data from online(web/mobile) and offline interactions would allow the brand to develop advanced personas that can then be deployed in personalized marketing.
Tools such as iJento, Tealium, and Adobe Insights provide varying degrees of capabilities when it comes to server-side tagging.
Summary
Small businesses may never have an immediate need for implementing advanced digital measurement infrastructures but would like to at least be aware of the options. Mid-sized companies may have clarity about the specific analysis needs but lack the knowledge (or budget!) to get there. Large companies may have both the need and the knowledge but might lack the roadmap that incrementally on-boards analytics rigor in line with business priorities and resource constraints. Regardless of the context though, as Digital Marketers, it serves us a very valid purpose to at least have a perspective of the various approaches (and the pros and cons of each) that can be leveraged to put in place robust digital insights capabilities.
Article purpose
A best-practice guide designed to introduce readers to the various types of website data collection architectures using Tag Management. A ‘top-of-the-funnel’ piece meant to project subject matter depth and provoke customer interest specifically from Enterprise customers looking for more flexible and less disruptive methods of website data collection.
About the Client
A leading, US-based Web Analytics providers focusing specifically on technology implementations of Google Analytics, Adobe Analytics, Digital data warehouses and Enterprise Tag Management solutions.